Java(40) - 컬렉션 프레임워크
1. 컬렉션 프레임워크
컬렉션 프레임워크란,
- 프로그램 구현에 필요한 자료구조와 알고리즘을 구현해 놓은 JDK 라이브러리
- java.util 패키지에 구현되어 있다
- 개발에 소요되는 시간을 절약하고 최적화된 라이브러리를 사용할 수 있다
- Collection 인터페이스와 Map 인터페이스로 구현되어 있다
입니다.
자료구조는 (Data Structure)
- 프로그램에서 사용할 많은 데이터를 메모리 상에서 관리하는 여러 구현 방법들
- 효율적인 자료구조가 성능 좋은 알고리즘의 기반이 된다
- 자료의 효율적인 관리는 프로그램의 수행 속도와 밀접한 관련이 있다
- 여러 자료구조 중에서 구현하려는 프로그램에 맞는 최적의 자료구조를 활용해야 하므로
자료구조에 대한 이해가 중요하다
즉 자료구조는 메모리 위에 data들이 있는데, 그 data들을 어떤 구조로 효율적으로 관리할 것인지
정해놓은 방법입니다.
2. Collection 인터페이스
Collection 인터페이스는 하나의 객체의 관리를 위해 선언된 인터페이스로
필요한 기본 메서드들이 선언되어 있습니다.
하위에 List, Set 인터페이스가 있습니다.
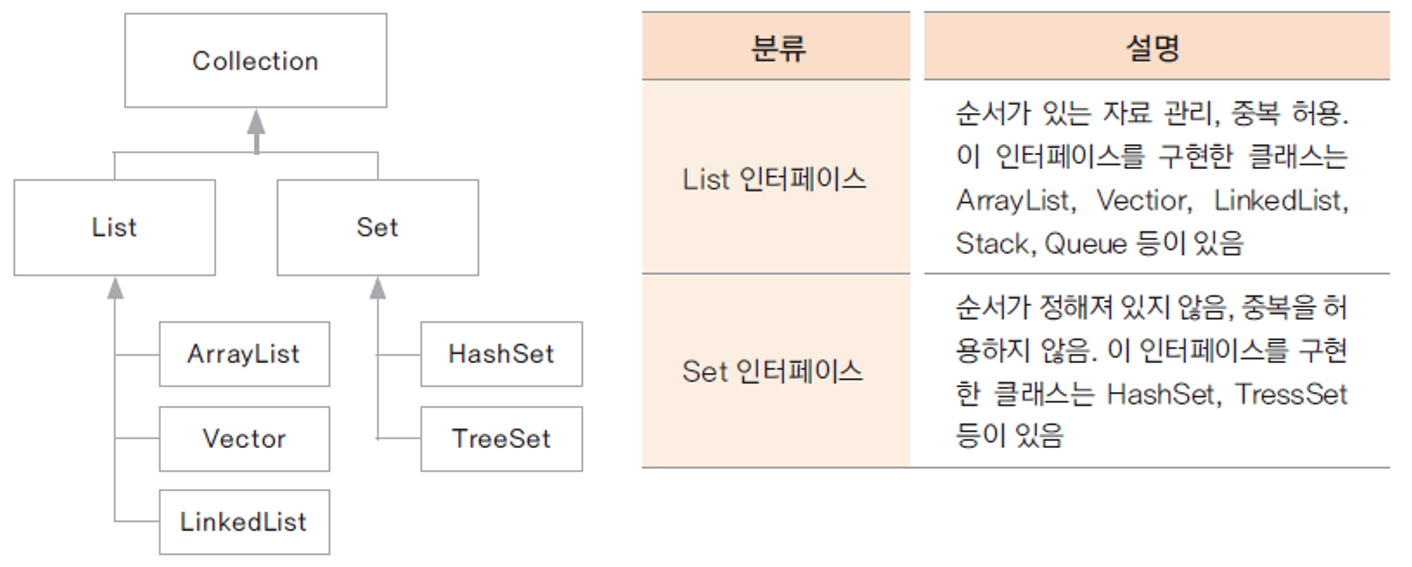
즉 Collection 인터페이스는 하나의 객체에 대한 자료구조입니다.
딱 하나씩을 어떻게 관리할 것인지에 대한 자료구조입니다.
3. Map 인터페이스
Map 인터페이스에는 쌍으로 이루어진 객체를 관리하는데 필요한 여러 메서드가 선언되어 있습니다.
Map을 사용하는 객체는 key-value 쌍으로 되어있으며, key는 중복될 수 없습니다.
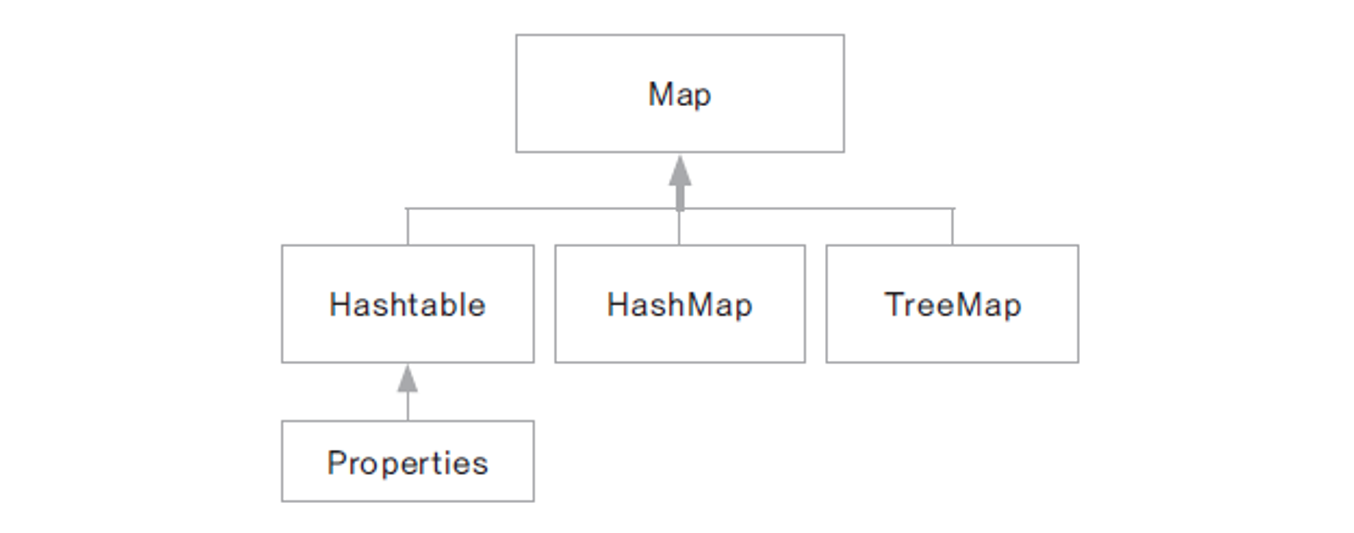
Collection, Map 인터페이스는 뒤에 포스트에서 자세히 다루겠습니다.
4. 자료구조
기본적인 자료구조에 대해 설명하겠습니다.
-
배열(Array)
배열은 앞에서 배웠듯이 연속된 자료구조이자 선형 자료구조입니다.
선형 자료구조는 앞, 뒤의 요소가 1대1의 관계에 있는 것을 의미합니다.
배열의 특징으로는 논리적, 물리적 구조가 동일하다는 것입니다.장점은 i번째 요소의 접근이 매우 빠르다는 것입니다.
(인덱스 연산)
단점은 배열 중 한 요소가 빠지거나 더해지면 당기거나 밀어주는 연산이 필요합니다.
(fixed length)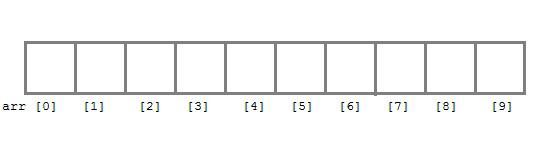
-
연결 리스트(Linked List)
연결 리스트 역시 선형 자료구조 입니다.
배열과 다르게 논리적 구조, 물리적 구조가 동일하지 않습니다.
자료와 주소(링크)로 구성되어 있습니다.장점은 요소가 하나 빠지거나 더해질 때 링크만 해제해주거나, 연결해주면 됩니다.
즉 길이(length)의 변화가 유연합니다.
단점은 i번째의 요소 접근시 하나씩 확인하면서 가야하기 때문에 접근이 느립니다.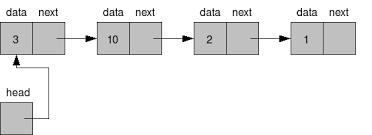
-
스택 (Stack)
스택 역시 선형 자료구조입니다.
LIFO(Last In First Out)의 구조를 가지고 있습니다.
즉 후입 선출로 먼저 들어간게 나중에 나오는 구조를 가집니다.주요 메서드로는 push()와 pop()이 있고 각각 넣고 빼는 기능을 합니다.
스택은 ArrayList나 Vector로도 구현이 가능합니다.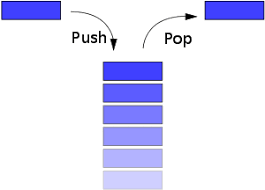
-
큐(Queue)
큐 역시 선형 자료구조입니다.
FIFO(First In First Out)의 구조를 가지고 있습니다.
즉 선입 선출로 먼저 들어간게 먼저 나오는 구조를 가집니다.주요 메서드는 enqueue(), dequeue()가 있고 넣고 빼는 기능을 합니다.
보통 우선순위 큐를 사용하거나, ArrayList나 Vector로 구현이 가능합니다.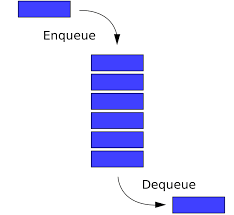
-
해시(Hash)
해시는 검색을 위한 자료구조입니다.
위의 자료구조와는 다르게 비선형 자료구조입니다.index = hash(key)로 나타내며, hash(key)는 해시 함수(hash function)입니다.
key값을 주게되면 위치(index)를 주는 자료구조입니다.해시 테이블(hash table)은 해시의 key값과 value값을 저장하는 자료구조입니다.
접근이 굉장히 빠르다는 특징이 있으며, key값은 중복되지 않습니다.
해시에 관한 것은 뒤에서 더 자세히 다루겠습니다. -
트리 (Tree)
트리는 비선형 자료구조입니다.
부모 노드와 자식 노드간의 연결로 이루어진 자료구조입니다.jdk클래스에 TreeSet, TreeMap 클래스가 있으며, 정렬을 지원합니다.
-
이진트리 (Binary Tree)
이진트리는 비선형 자료구조입니다.
부모노드 하위의 자식 노드가 2개보다 작거나 같은 경우의 트리입니다.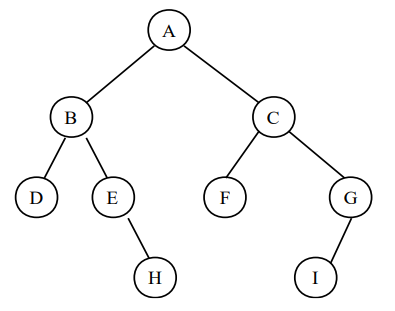
검색을 위해 사용하는 특별한 이진트리가 있는데, BST(Binary Search Tree)가 있습니다.
BST는 이진트리와 특징은 같지만 같은 데이터를 넣을 수 없으며(중복 x)
부모 노드보다 작은 경우 왼쪽에, 큰 경우 오른쪽에 값을 넣습니다. -
힙(heap)
힙은 우선순위 큐(Priority Queue)를 구현한 자료구조 입니다.
Max Heap은 부모 노드가 자식 노드보다 항상 크거나 같은 값을 갖는 경우입니다.
Min Heap은 부모 노드가 자식 노드보다 항상 작거나 같은 값을 갖는 경우입니다.Complete Binary Tree 라는 특징이 있습니다.
보통 heap 정령에 활용합니다.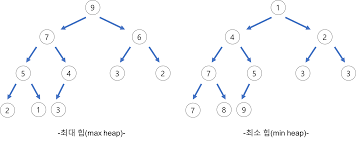
-
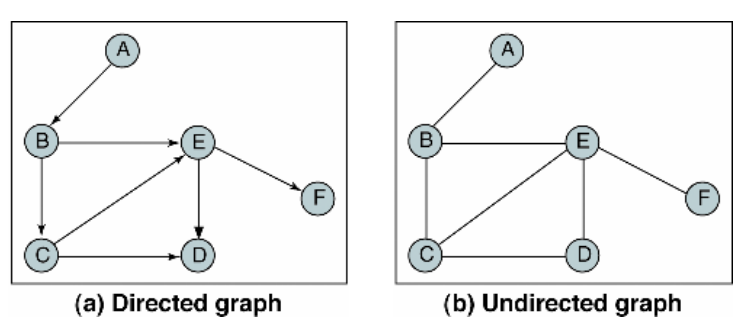
그래프(Graph)
그래프는 정점(vertex)과 간선(edge)들의 유한 집합입니다.
(G = (V,E))정점(vertex)는 여러 특성을 가지는 객체, 노드입니다.
간선(edge)는 정점(객체)들의 연결 관계를 나타내는 선입니다.
(링크)간선은 방향성이 있는 경우와 없는 경우가 있습니다.
댓글남기기